


The average person in modern society has probably interacted with a browser and has typed in domains that reference's IP's, but has no inkling how it all works with one another. Not sure what these terms mean? Great, then this article is just for you!
In this article, I cover a broad scope of the journey from typing a website URL in your browser (such as github.com) to returning a web page. To understand how network devices communicate, we start with the core concept of protocols and TCP/IP.
N.B: All terminology in this article will be explained in more detail in the Technical Dictionary at the bottom of the page
Protocols
Protocols are sets of rules and conventions that define how data should be transmitted, received, and interpreted between devices on a network, particularly the Internet. It is like having grammar applied to a language, if you don't have periods(.) or commas(,), your message may be misunderstood. There are several protocols such as FTP (File Transfer Protocol) and SMTP (Simple Mail Transfer Protocol). But in the context of this article, we will Be Focusing on HTTP (Hyper Text Transfer Protocol).
HTTP is a protocol that exists within the application layer of the TCP/IP and OSI Model (these will be covered in the next section). HTTP protocols transmit data between a client and a server. The client in this case is the browser and the server is the web server. When an HTTP request is sent, the web server would reply with static content (a web page) or an error page and status code. Since HTTP returns static content as readable text, it is best practice to use HTTPS instead, which is the secure version of HTTP that encrypts the data.
TCP/IP
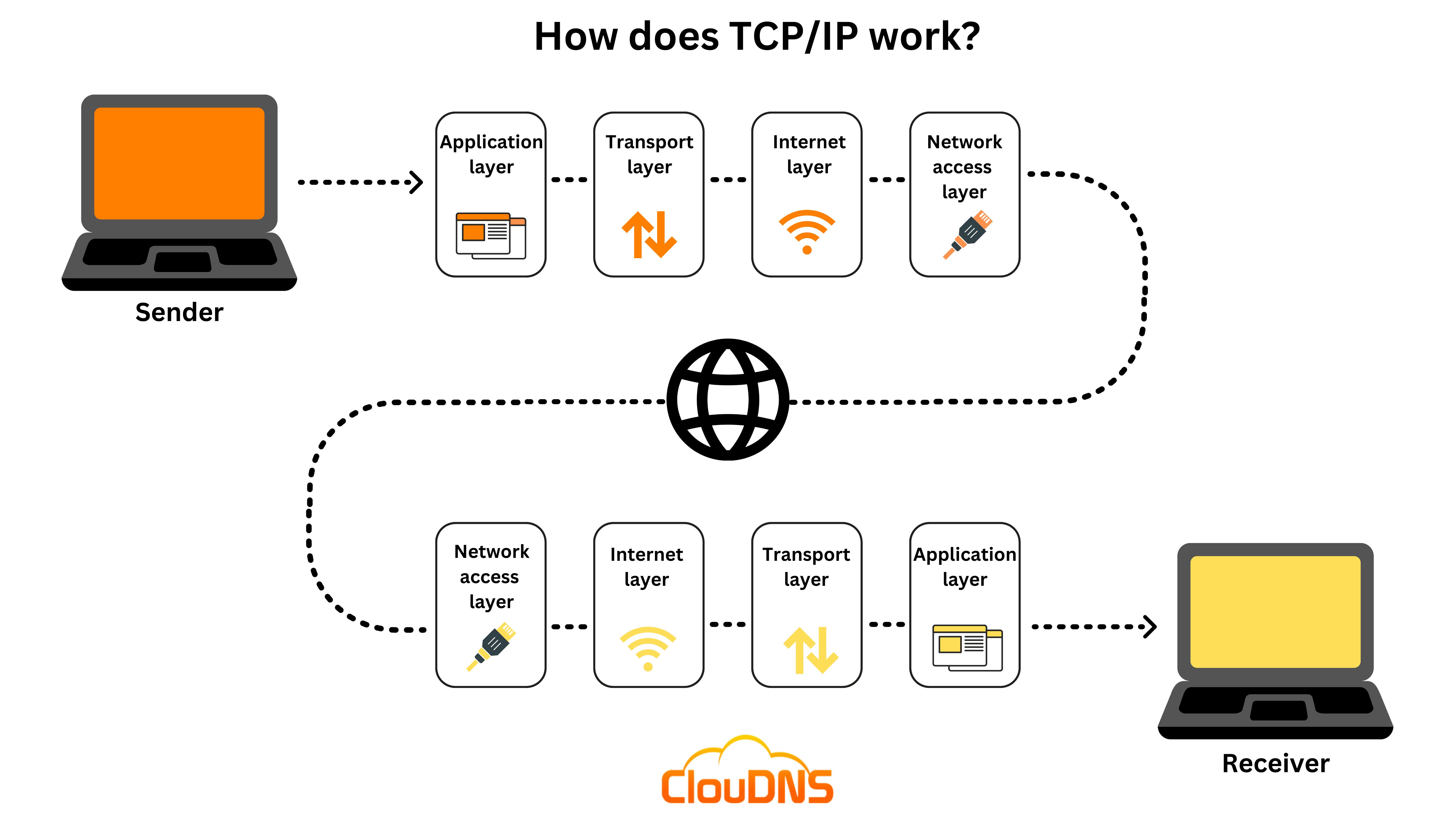
TCP/IP (Transmission Control Protocol/ Internet Protocol) is defined by 4 layers and several protocols that describe how devices communicate from the highest level (Application Layer) to the lowest level (Link Layer).
Application Layer
This layer contains protocols that describe how data should be formatted, presented and exchanged. These are some of the protocols:
-> HTTPS: in our example when we type in google.com, it automatically uses an HTTPS protocol to request Google's main page even if we don't specify the protocol ourselves because that's how their web server is configured.
-> DNS: to get the IP address of google.com we need to query the DNS nameservers
Transport Layer
The transport layer controls end-to-end and defines how connections are made and destroyed. Two main protocols reside in this layer:
-> TCP (Transmission Control Protocol): ensures a reliable connection, where no data is lost, corrects errors and flow of data. This type of connection may be used for downloading files, in which we need to ensure no data is lost during the connection
-> UDP (User Datagram Protocol): It is an unreliable connection, where data may be lost, but is faster than TCP. It may be used for online streaming or gaming.
Internet Layer
this layer is responsible for routing data packets from source to destination across networks. It uses IP addresses to identify devices to which to send this data and determine the best path for data to travel.
Link Layer
The link layer is the lowest layer defined by physical connections (Ethernet, Fibre optics, Coaxial) and also the addressing of devices (MAC addresses). Once you type
google.com, you need access to the internet to make any HTTP requests. To access the internet you need a modem and a router. Most modern Wi-Fi routers come with both built-in (differences between modem and router). Devices (your PC and router) have NIC (Network Interface Cards) that contain MAC (Media Access Control) addresses. Allowing devices to transmit data between one another wirelessly or via Ethernet.
Structure of a URL
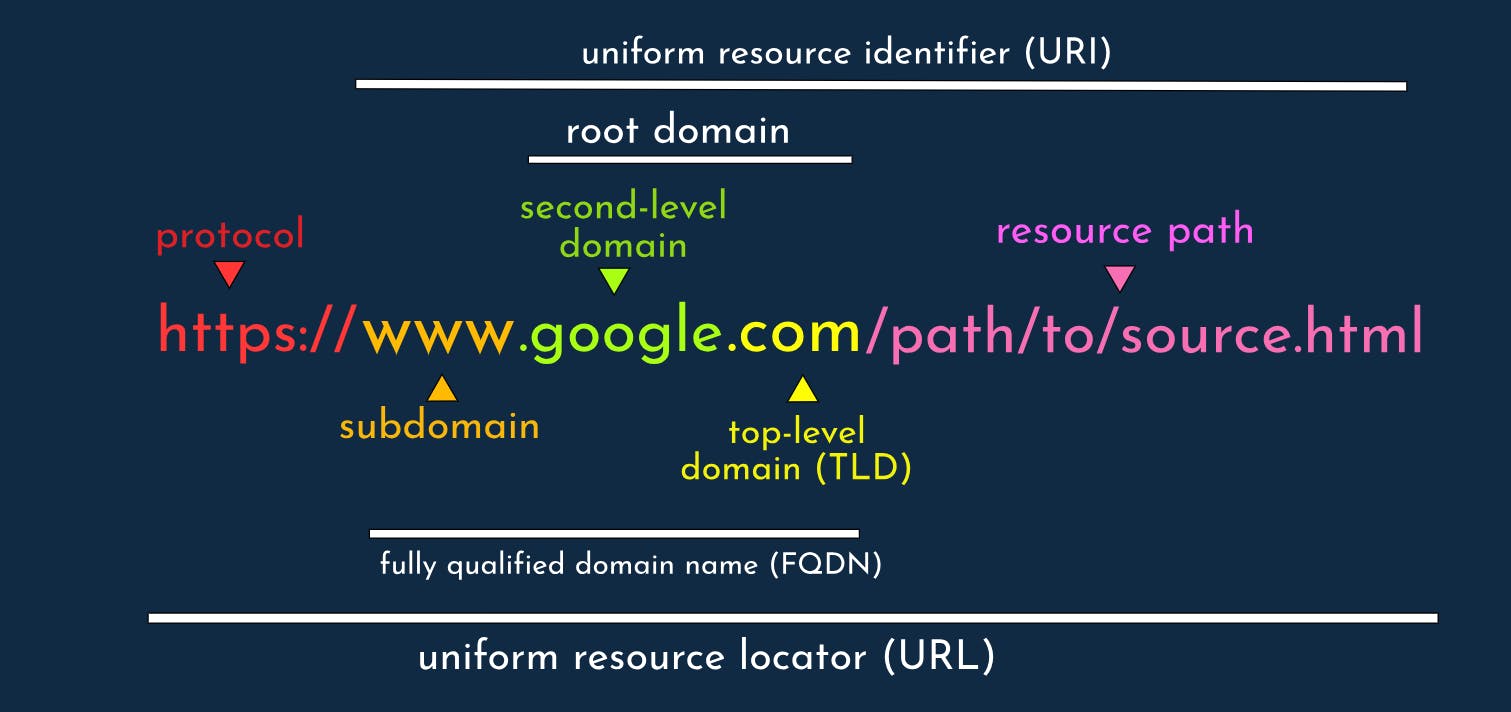
You might be used to typing a site name such as youtube.com without specifying other parameters. This is because these small details are managed by the web servers. In this section, we will take a deeper look at the structure of what is typed inside a browser to access a website or service.
To identify and access a resource on the internet, the browser needs to know the site's URL (Uniform Resource Locator). An example of a URL is shown above with the general format: protocol->domain_name->path . We covered protocols in the previous section, so what is a domain name? Domain names provide a convenient way for humans to identify and remember resources on the internet. Domain names are mapped to an IP (a physical or virtual device network address, see more in the technical dictionary). The structure of an IP can prove difficult for the human brain to remember, for example, it would be easier to remember youtube.com rather than one of its IPs 208.65.153.238.
Domains are mostly structured in the following way: subdomain.second-level-domain.tld. The subdomain such as www or blog in a website such as blog.example.com provides a way to section content provided by a web server. for instance, maybe you prefer to have your home page on www.mysite.com and your blog page on blog.mysite.com. Next is the second-level domain name, which is the domain name that you create, and must be unique when in context to your TLD. TLDs (Top Level Domain) provide a short way to describe what content is on your website. For instance, .edu for educational sites and .gov for official government sites.
Lastly is the path. If you don't want to section content by subdomains, paths are another way to access different sections of a webpage, for example, to access my profile on my website, the path may be: mywebsite.com/profiles. However this is not usually explicitly used, most resources are navigated via the website itself rather than through its path.
Domain Name System
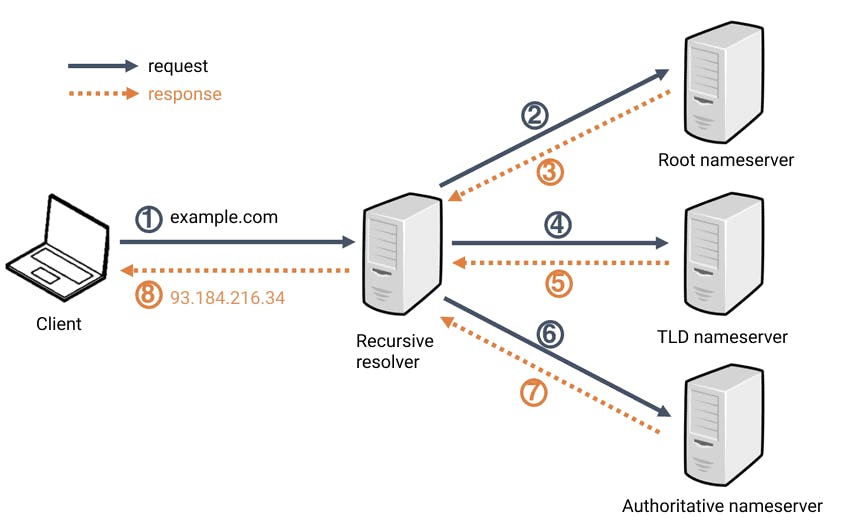
In the previous section, the DNS was mentioned as being responsible for mapping a domain name to an IP. The DNS is like a phonebook that keeps records of all domain names and their relative IPs. Here we will look in detail in terms of how we can get an IP from a domain name once it is registered.
When you type in google.com it first passes through to a Recursive resolver. This is usually used by your ISP or a 3rd party DNS service provider, where it acts as a middleman between the client and the DNS nameserver. It responds with cached data of recent queries or sends a request to the Root nameserver, followed by the TLD nameserver and finally the Authoritative nameserver.
A Root nameserver directs the Recursive resolver to a website's respective TLD nameserver concerning the website's TLD (.com, .io, .org, .uk ...). There are 13 types of Root nameservers with multiple copies spread throughout the world.
A TLD nameserver, for example, a .org TLD nameserver will contain all the information of websites ending with .org. It will redirect the Recursive resolver to an Authoritative nameserver.
The Authoritative nameserver is the last stop for the Recursive resolver. It has information specific to the domain name google.com and will return information in the A/ AAAA record via recursive resolver back to the client, thus returning the website's IP. For Google it's 8.8.8.8. For more info on DNS records like A, AAAA and CNAME see DNS records.
Servers
What is a server? The term was previously mentioned in this article, so before moving on let's clear any doubts. A server is anything that provides a service to a client. In the context of Networking, it's any computer hardware or software that provides data, resources or programs (The service) to other computers (The client) over a network. A simple example would be having a dedicated computer in your business with the sole purpose of hosting files. The computer will be the server and the employees who use phones or computers to access these files will be the client, the files are the service being provided. When you type in a web URL like google.com, we access 3 types of servers: a Web Server, an Application Server and a Database Server.
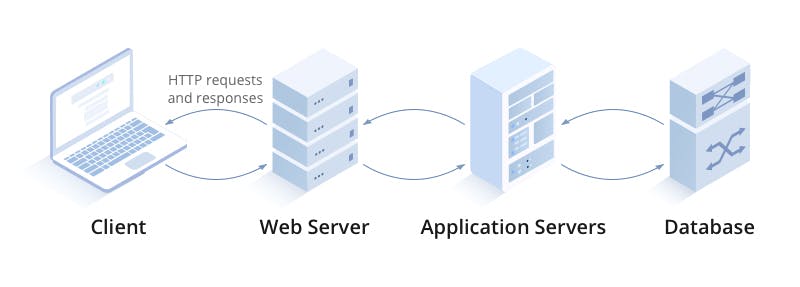
Web Server
A Web Server's job is to serve "static" content to the client. Static content means it does not change, for instance, HTML and CSS files, images, videos and other resources. This content is stored on the server, or references to this content on the web. It does not need much computational power to generate new content as it is already there.
When you type google.com, you access the web server being hosted on that IP address, the web server will then return its corresponding HTML and CSS files to view the web page. Examples of popular web servers include NGINX and Apache.
Application Server
An Application server performs provides "dynamic" content to the client. This means any content that needs to be generated such as a calculation or a list of results from a database. Application servers often interact with databases and APIs to generate their content.
An example would be visiting www.wolframalpha.com. The web server would load the page, and when I request the website to do calculus operations for me, the web server will send a request to the application server. The application server would either perform the calculation itself via a program or query a 3rd party API to do it. It will then return the result to the web server so the client can view the results.
Database Server
A database is the storing of organized and structured data. In computers, databases can either be relational or non-relational (SQL or NoSQL). A Database Server runs a database management system (DBMS) like MySQL, ORACLE or Microsoft Access. These DBMS control access to data, as well as insertion, deletion and updating of its data. It is often interfaced by an application server.
If you visit a social media platform like Facebook or Twitter (X), your list of friends and followers is stored on a database, as well as posts and the likes on those posts.
Load Balancer
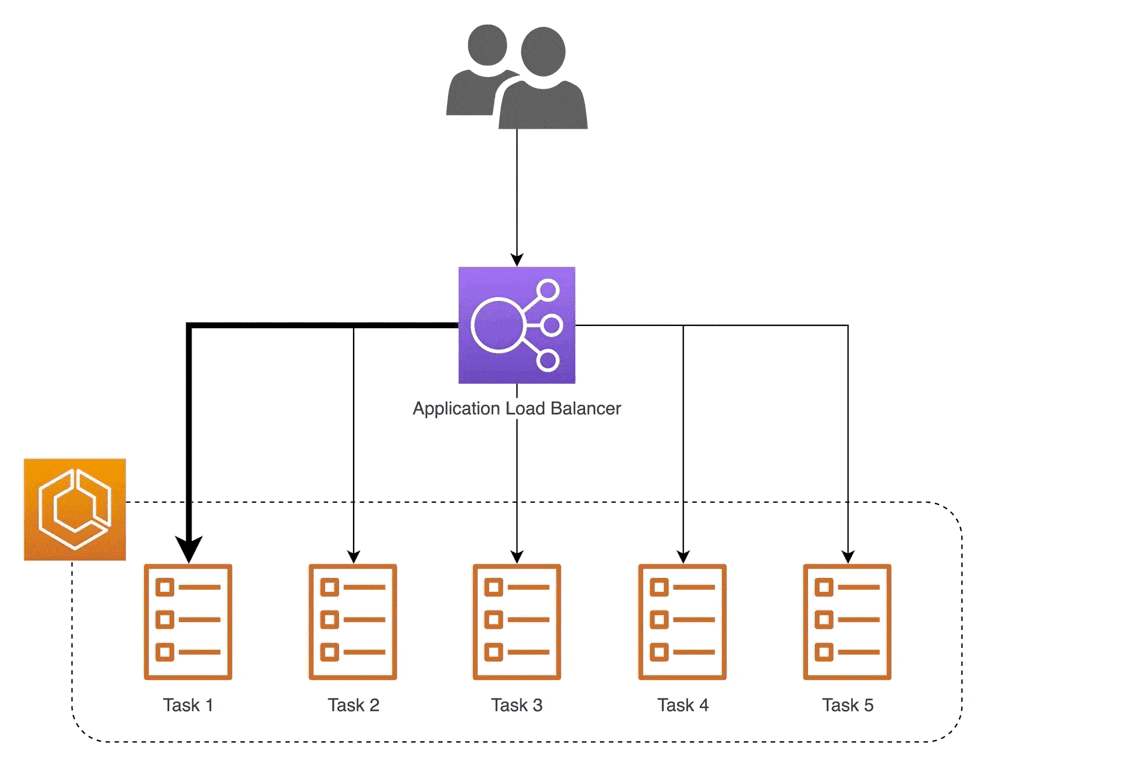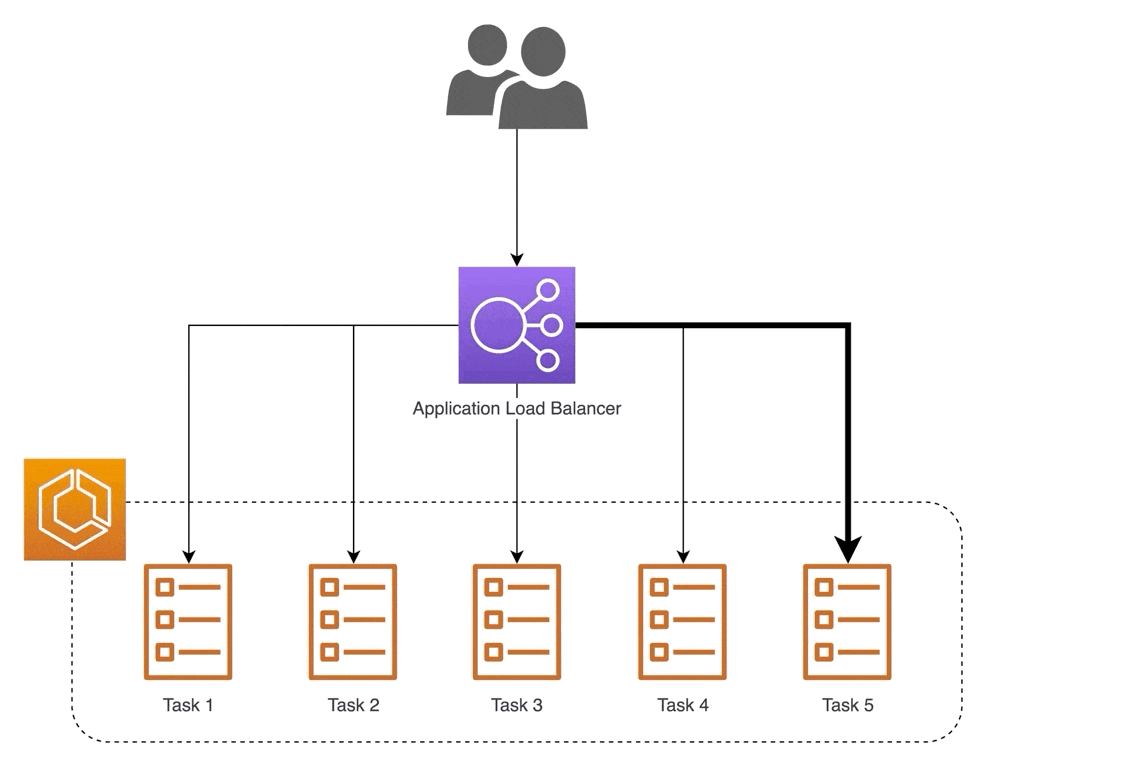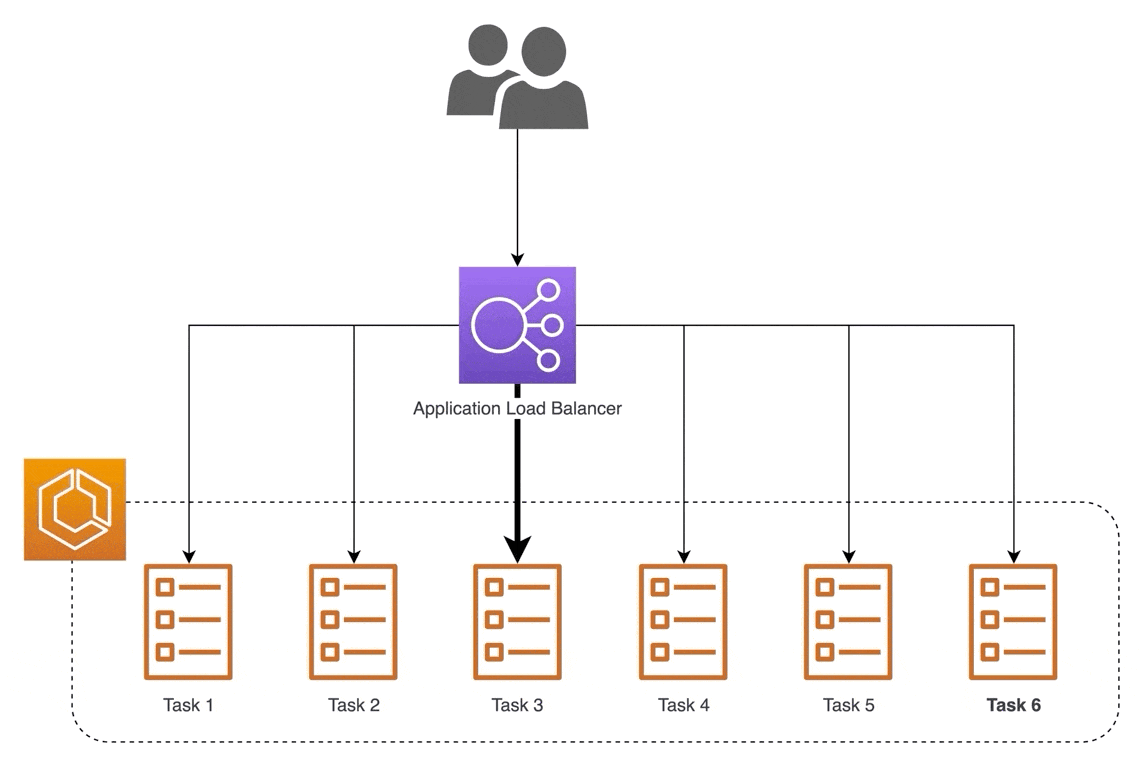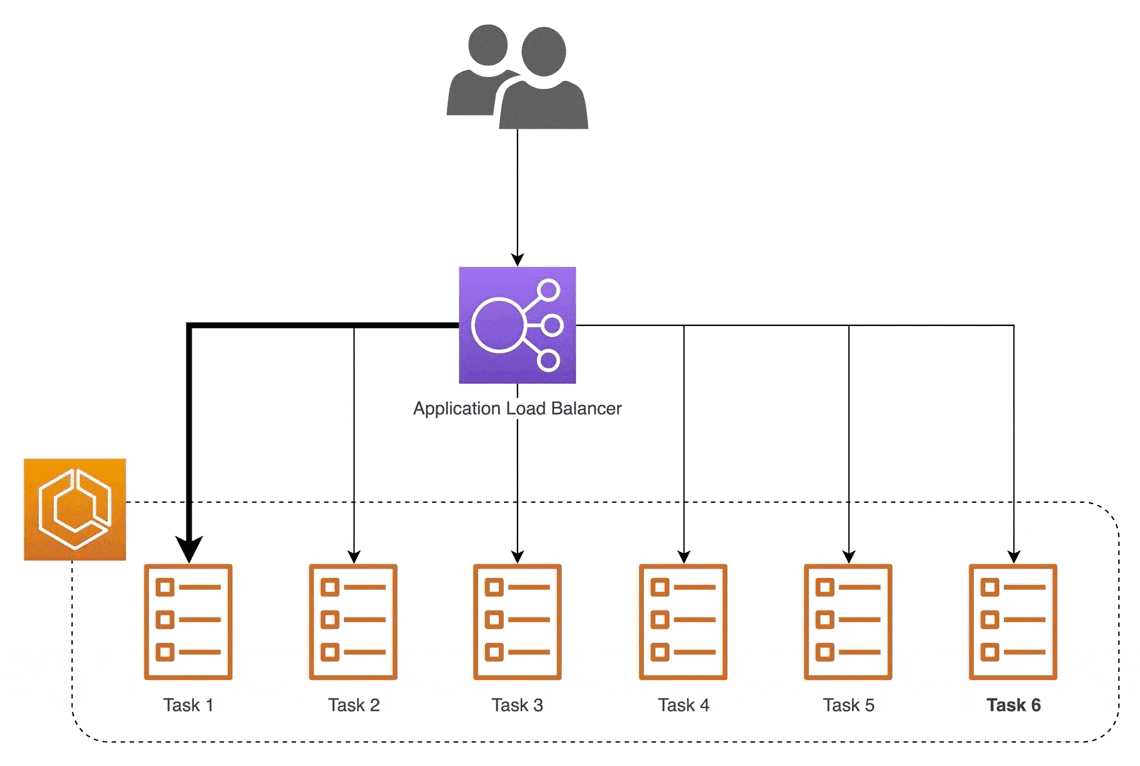
For websites that have millions of visitors every day, one server is not enough. Too much traffic could cause a site to be slow enough to be unusable. That's why it is important to have more than one server. More servers create system redundancy to reduce the chance of a single point of failure (SPOF).
Now we have an array of servers, so how do we manage them? That's where the load balancer comes in. The load balancer acts as an intermediary between a client and server, efficiently distributing the traffic from clients to the servers. There are hardware load balancers and software load balancers that can easily run on a virtual server. There are also many load-balancing algorithms to distribute traffic with the most common one being round-robin, which sequentially distributes traffic between servers for every new client request.
Security
Threats from hackers, bots and malicious programs place high importance on network security. With today's standards, it's impossible to create a website that accepts personal user info like credit card numbers and passwords without extensive security measures. There are two ways to keep a network secure: SSL/TLS (secure connection) and Firewalls (virus and threat prevention).
SSL/TLS

Previously HTTPS was mentioned as the secure version of HTTP. Since HTTP sends plain readable text over the network it is insecure. HTTPS can send encrypted data over a network with the use of public and private keys. It does this through SSL ( Secure Socket Layer) / TLS (Transport Layer Security). TLS is the updated version of SSL without its security flaws but they both operate the same way.
For clients to identify a server as secure, the server must first verify its identity with a Certificate Authority (CA). The Certificate Authority has a private and public key. The CA's public key is available to everyone and is preinstalled on your browser, so every client will have a copy of the public key. The server generates a Certificate Signing Request (CSR) to be verified by the CA. The CSR will contain the server's private and public key. The CA will inspect the information on the CSR, and if validated, will use its private key and the information found in the CSR to generate a certificate for the server.
Once the server has a valid certificate signed by the CA, clients (browsers) who visit the server will request its certificate to see if the server can be trusted. Because browsers have the CA's public key preinstalled, they can verify these certificates as legitimate and initiate a secure session with the server. You should see a padlock on your browser like the image above to confirm the session is secure. E-commerce sites like Amazon need to be certified for customers to share sensitive information. Some countries enforce by law for ISPs to filter out any websites without any certification.
Fire Walls
Firewalls are network security devices that monitor and filter both incoming and outgoing traffic to prevent malware and cyber attacks (this can range from viruses to spyware). Firewalls can be both hardware devices or software-coded and they operate on a set of security rules. One of the few ways firewalls protect your devices is to manage your computer's ports and filter incoming data packets. It is paramount that both servers and clients have firewalls.
Diagram Overview
This section will contain a simple web infrastructure design of all the topics we have discussed so far.

Here we have a client trying to access google.com. We confirm the domain's IP with our ISP's recursive resolver by verifying the A record from querying the root nameserver up to the authoritative nameserver. We then connect to Google servers using its IP, since it's certified we connect via HTTPS. The server IP we access ends up being a proxy server with a software load balancer installed (HAPROXY). The load balancer will redirect our traffic to any one of Google's servers. Each server block is protected by a firewall. In this conceptual scenario let's pretend each Google server block has both a web, application and database server hosted virtually. The web server will respond with Google's HTML page and any dynamic content from the application server and database if the client requests any.
Technical Dictionary
Network Protocol
IP (Internet Protocol)
MAC (Media Access Control)
NIC (Network Interface Card)
Data Packets
Internet Domain
URI (Uniform Resource Identifier)
URL (Uniform Resource Locator)
https:// and ftp://, as well as specifying a port such as: localhost:5500